Week #20
11 Mar 2019Summary of this week

I. Finding the learning rate
Put all the results got last week together, we get:
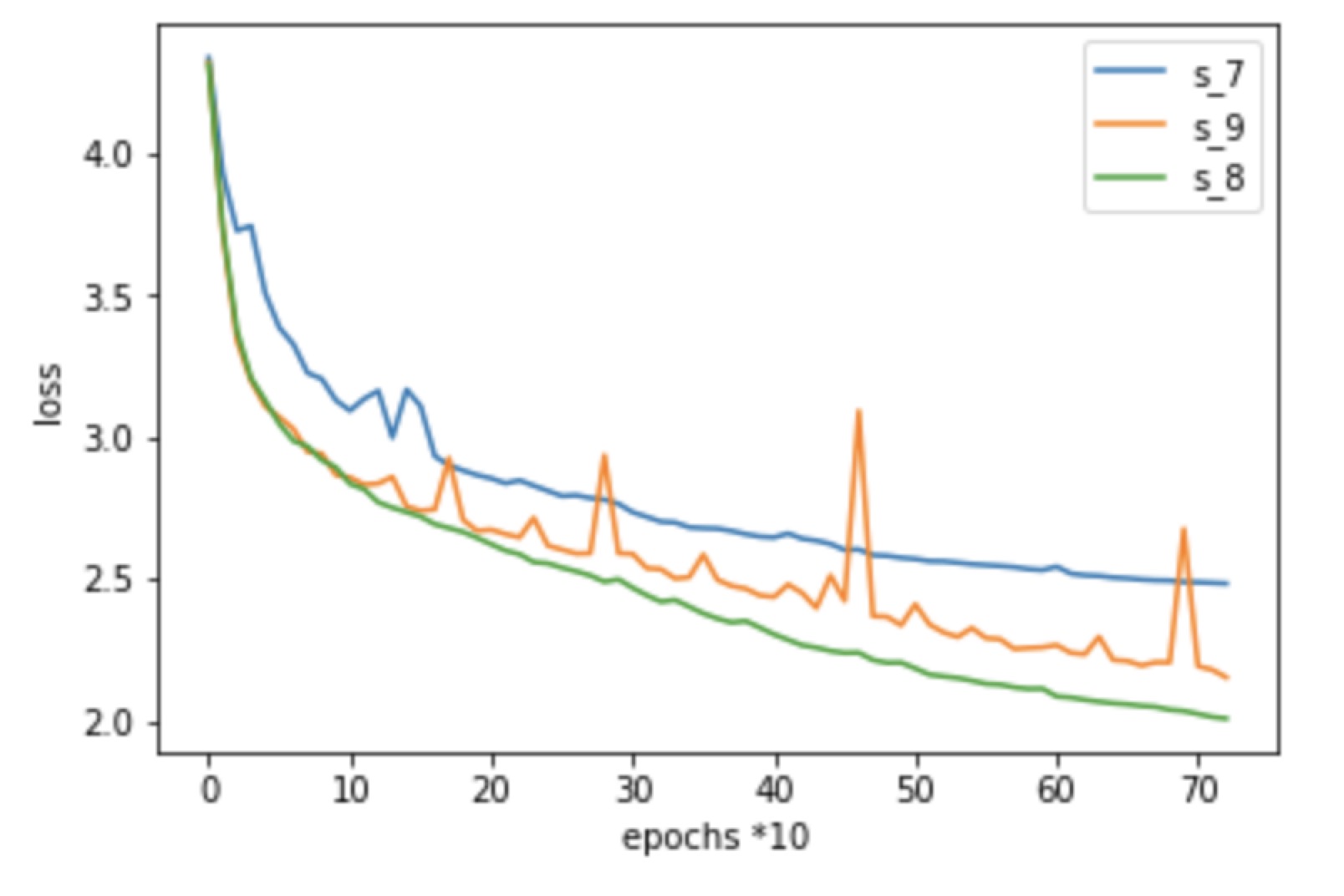
After 720 epoch, the minimum loss we could reach is 2.00.
Set four more experiments: (Check if for group 0,1,2, the weighted loss works fine) parameter number = 13,177,026
- Group 0, initial learning rate: 0.001, step_size = 100, gamma = 0.8, 350 epochs
Minimum Loss: 0.04022526
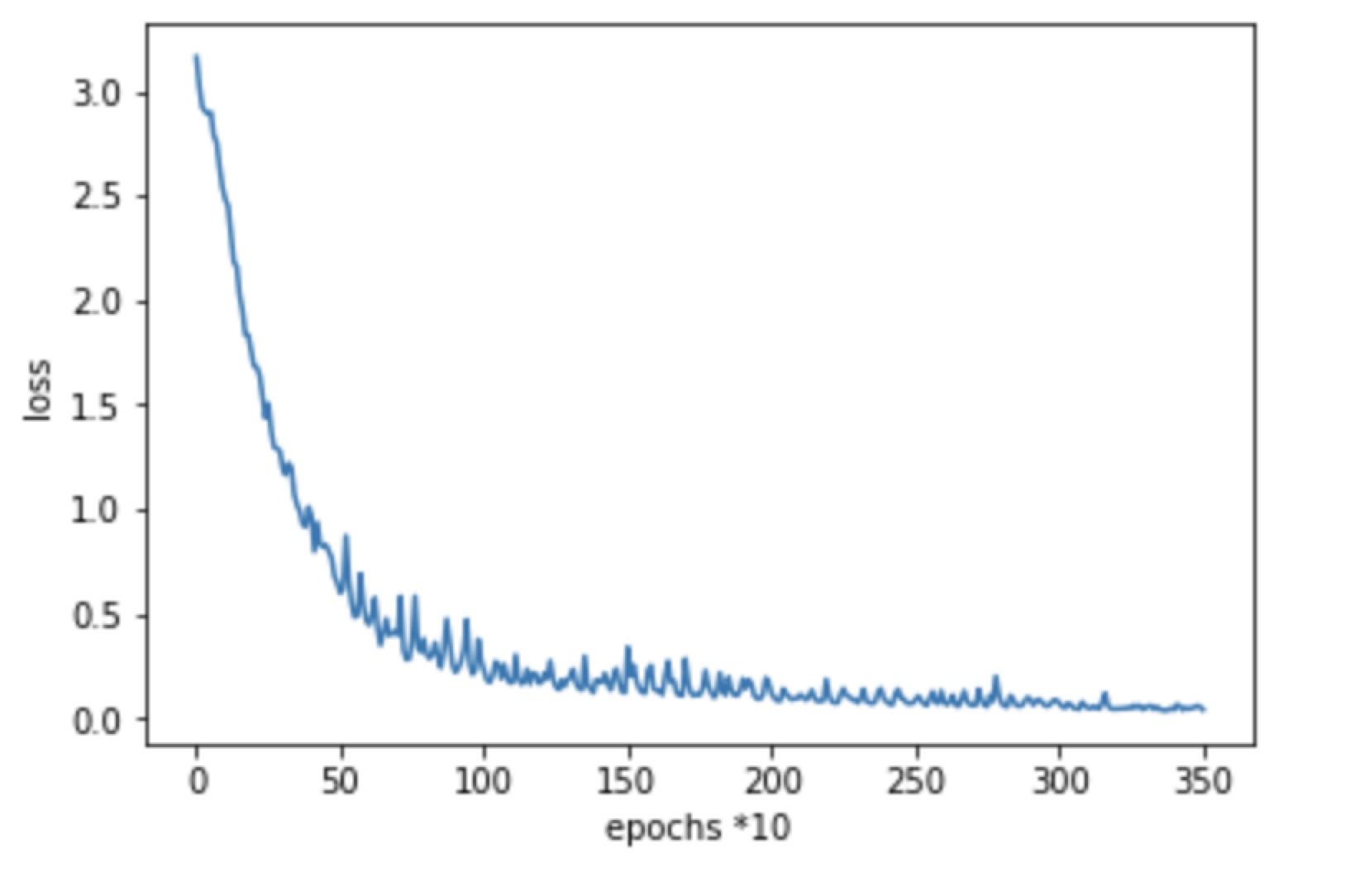
- Group 1, initial learning rate: 0.001, step_size = 100, gamma = 0.8, 350 epochs
Minimum Loss: 0.32910326
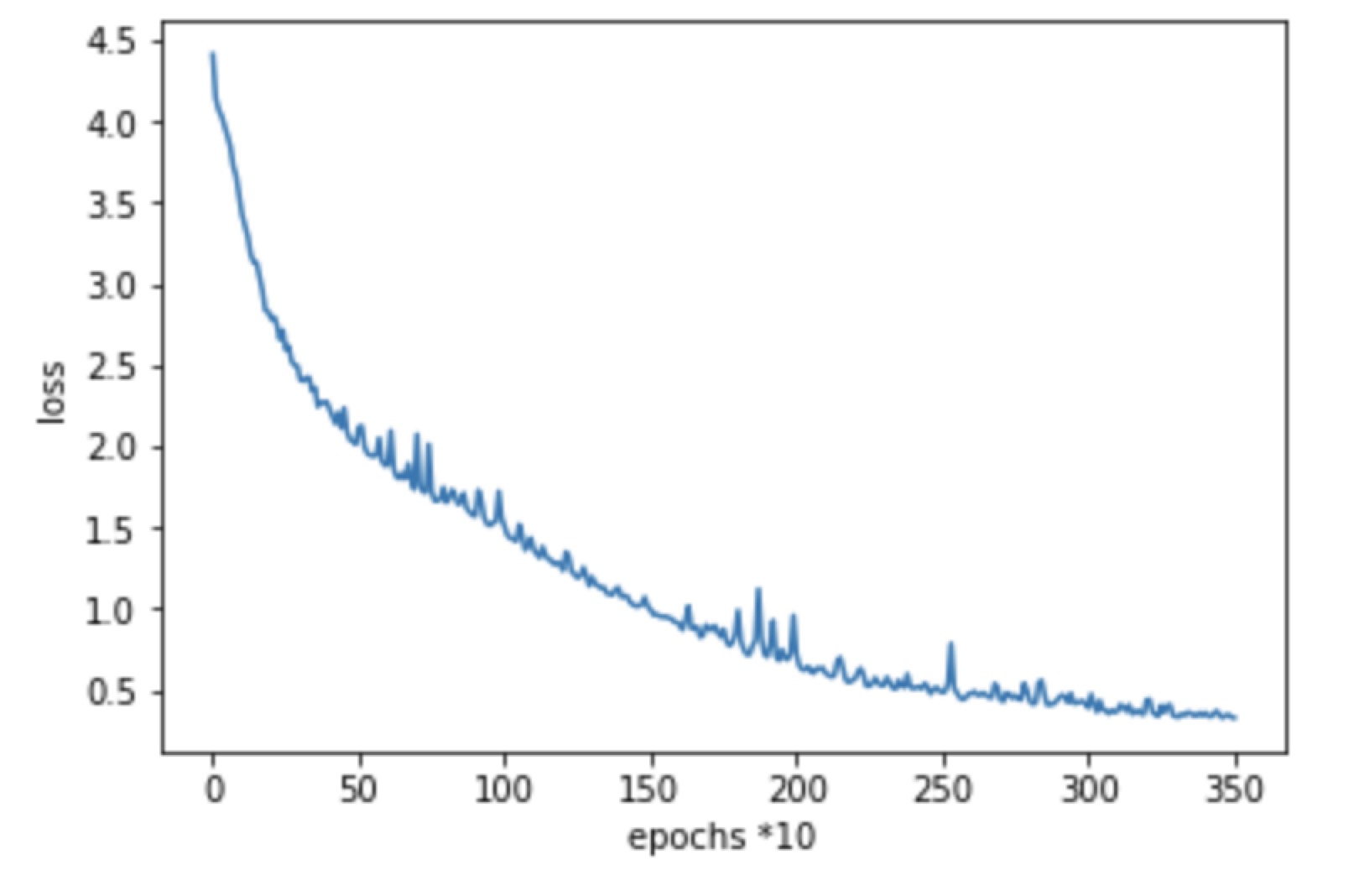
- Group 2, initial learning rate: 0.001, step_size = 100, gamma = 0.8, 350 epochs
Minimum Loss: 1.18046309
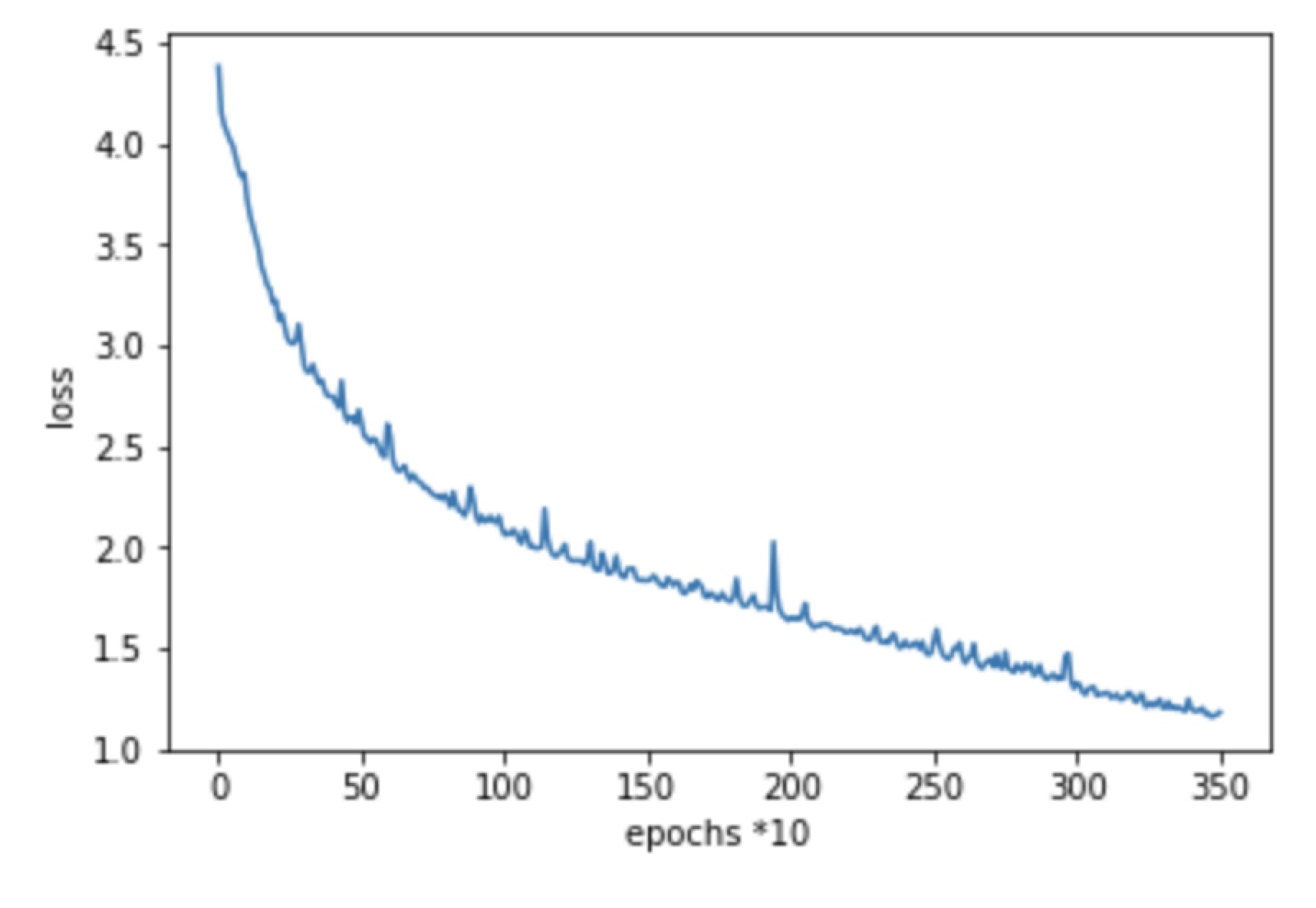
From these 3 experiments, we conclude that compared to the group 0, group 1,2 requires more epoch to converge to a loss that we desire. So increase the number of epochs may have a better result for the group 1 and later.
Modify the kernel size to 3
With a small kernel size, the computational expense will decrease, while our images are not large, so the experiments with small kernel size is operated. The configuration is as follows:
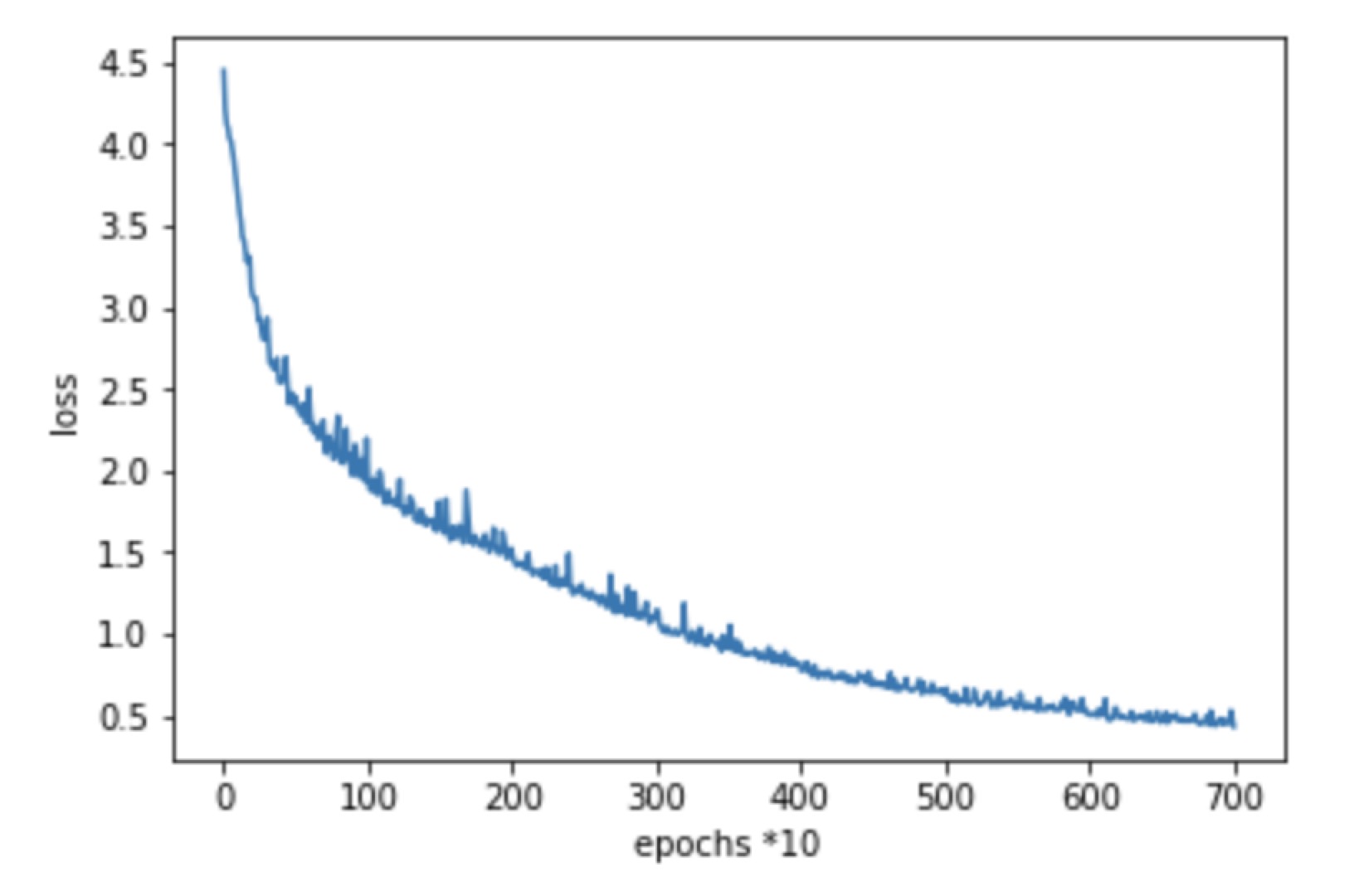
- kernel size = 3, parameter number = 5,046,466, slice1, initial learning rate: 0.001, step_size = 100, gamma = 0.85 Minimum Loss with 700 epoch: 0.434271; Minimum Loss with 350 epoch: 0.9511
II. Literature reading
During the experiments, I spent time exploring more articles. The reviews is here: