Week #10
02 Jan 2019- Try to normalize the data (mean subtraction and normalization) and then feed the CNN. The loss doesn’t decrease, and the visualization of the image segmentation after training is as same as before.
- The ground truth mask for the image’s size is the same as the input image, I’m trying to do a mapping of the data to class, But the dataset doesn’t provide the data mapping, so I tried another dataset called BMCC dataset, which only has 3 classes.
| Number | Data source | Training Sample | epoch of training | Batch size | learning rate | cropped size | momentum | Mimimum loss attained |
|---|---|---|---|---|---|---|---|---|
| 01 | KITTI | 480 | 20 | 1 | 0.25, every 5 epoch divided by 5 | 256 | 0.9 | 0.663 |
| 02 | KITTI | 480 | 20 | 1 | 0.25, every 5 epoch divided by 5 | 256 | 0.9 | 0.611 |
| 03 | KITTI | 480 | 100 | 1 | 0.005, every 5 epoch divided by 5 | 256 | 0.9 | 0.616 |
| 04 | KITTI | 480 | 20 | 4 | 0.005, every 5 epoch divided by 5 | 256 | 0.9 | 0.613 |
one example:
| Image | groundtruth | predicted mask |
|---|---|---|
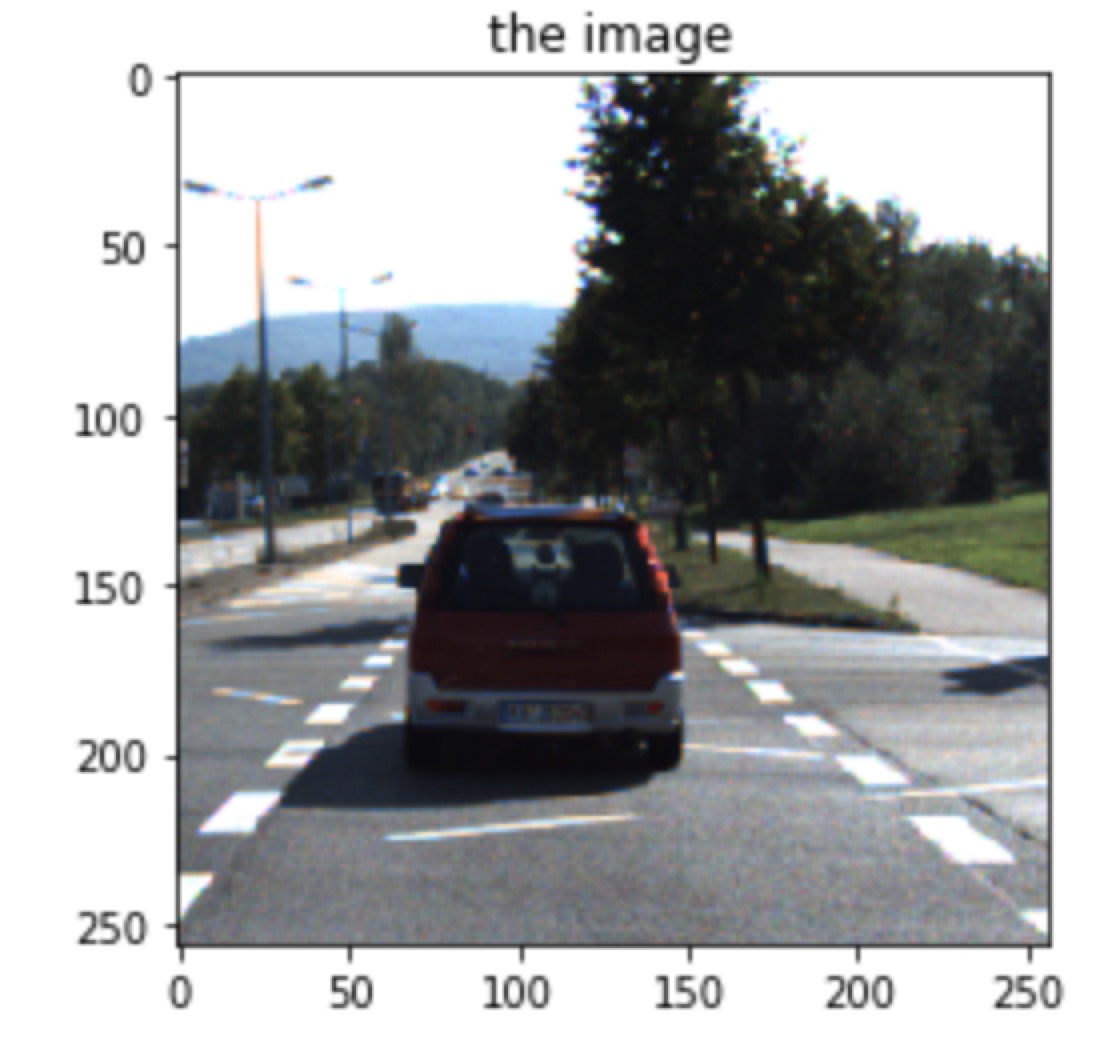 |
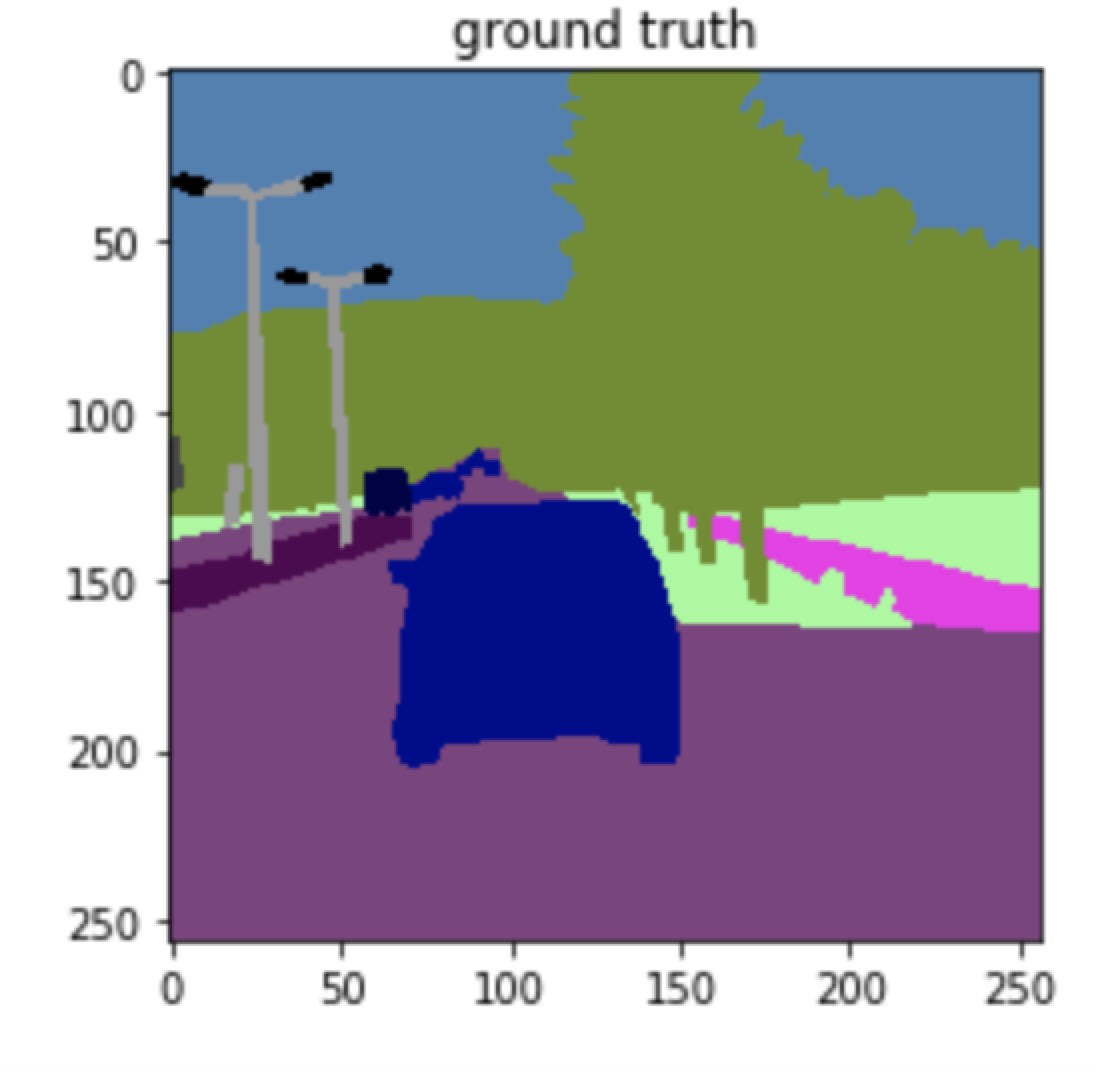 |
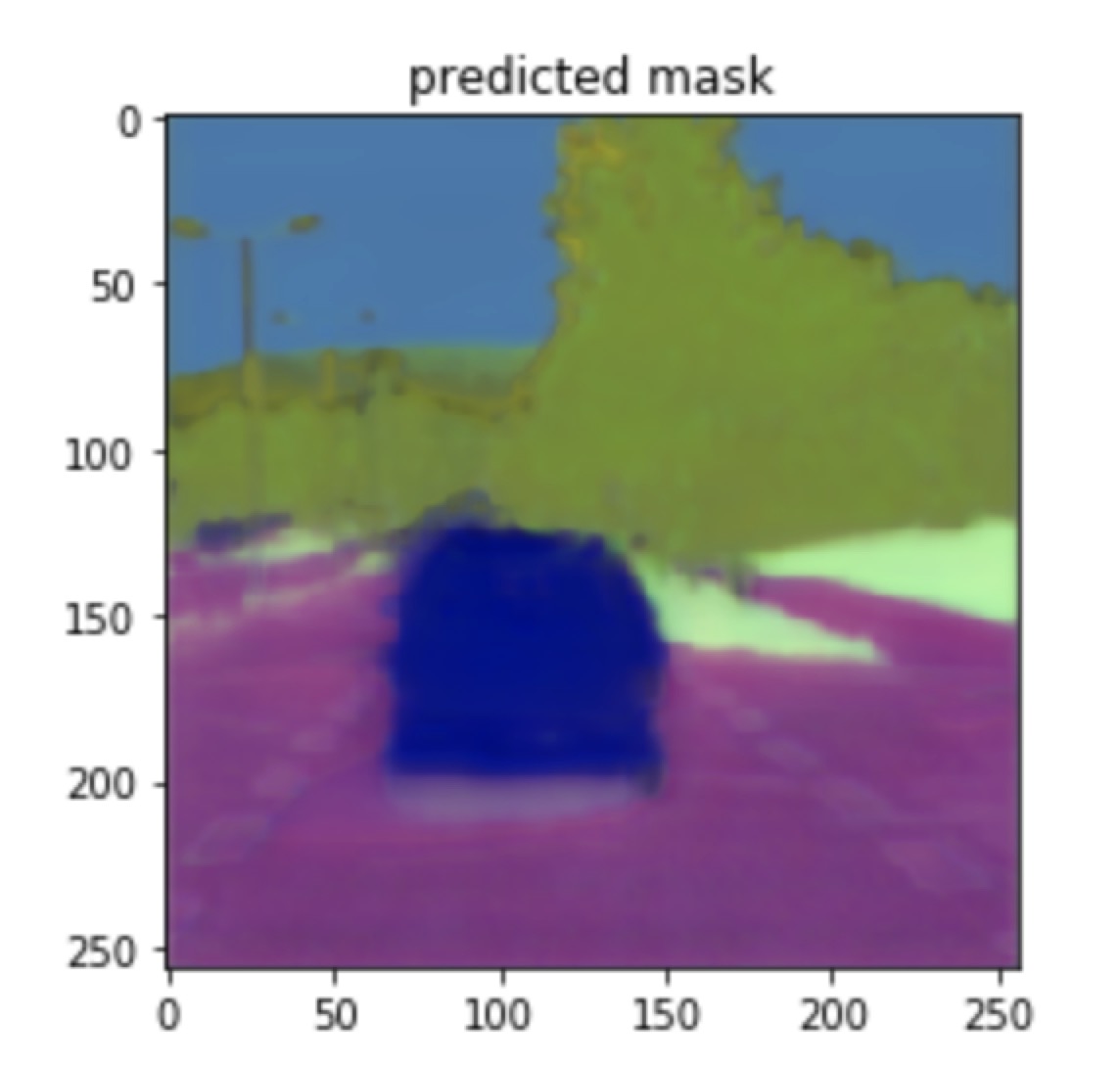 |
Question: I don’t understand in my all experiments, the loss doesn’t decrease but after training, the visualization of the predicted mask is similar to the groundtruth.
- Paper review of VNet:
- 3D image segmentation, input the 3d whole volume at once 128x128x64 voxel
- Novel objective function, which is based on Dice coefficient to balance the foreground and background
- Augment the data applying random non-linear transformations and histogram matching.
- use residual and unet Architecture
- Trained on 50 prostate MRI volumes and relative manual ground truth annotation from PROMISE2012 challenge dataset. (48h)
- momentum 0.99, initial learning rate 0.001, decrease by on order of magnitude every 25k iteration
- Test on 30 MRI volumes
Next step
- Implement VNet, DenseBlock using Pytorch